本文为作者原创文章,转载请注明出处。
工具
爬网页的一个很重要的工具就是对网页进行分析,所以熟悉Chrome的开发者工具使用很重要(其实很简单,不要被吓到。)
- 使用Chrome可以查看网页的html源码
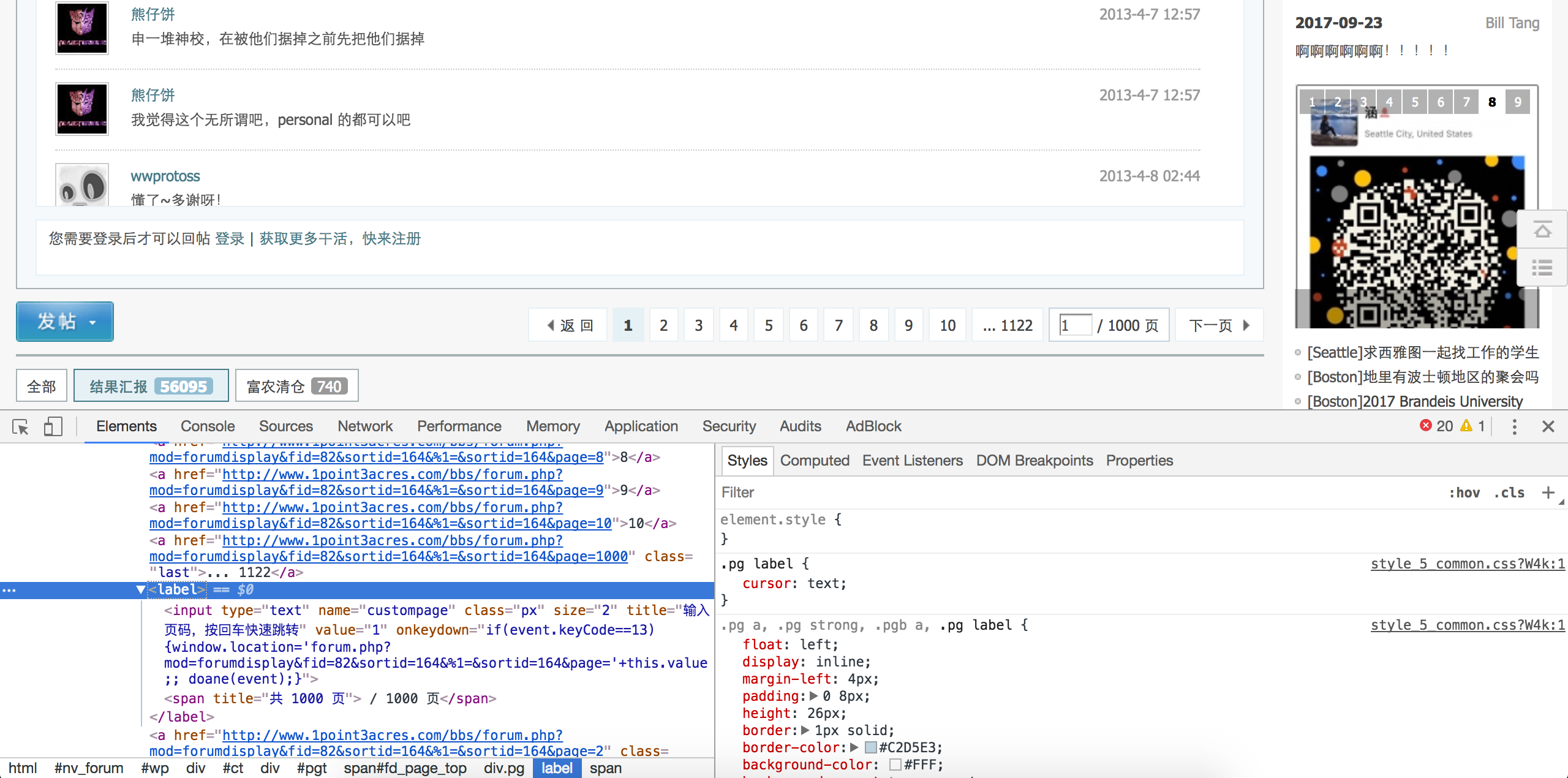
- 使用Chrome开发者工具可以查看网页指定部分的源码
Python包
Python有很多有用的爬虫工具包,这里只使用两个最基本的包(入门简单最好了)。
- urllib2
用来获取网页的源码。简单地可以理解为:你填一个url,它给你返回网页代码。 - pyquery
主要用来定位找到我们感兴趣的html代码。
案例背景
一亩三分地论坛上有很多留学申请的录取信息,包含申请者的三维条件和录取情况,可以用来分析学校的录取条件等信息。
步骤
获得我们要爬的所有网页的URL
http://www.1point3acres.com/bbs/forum-82-1.html这个网页是该论坛录取汇报的入口。
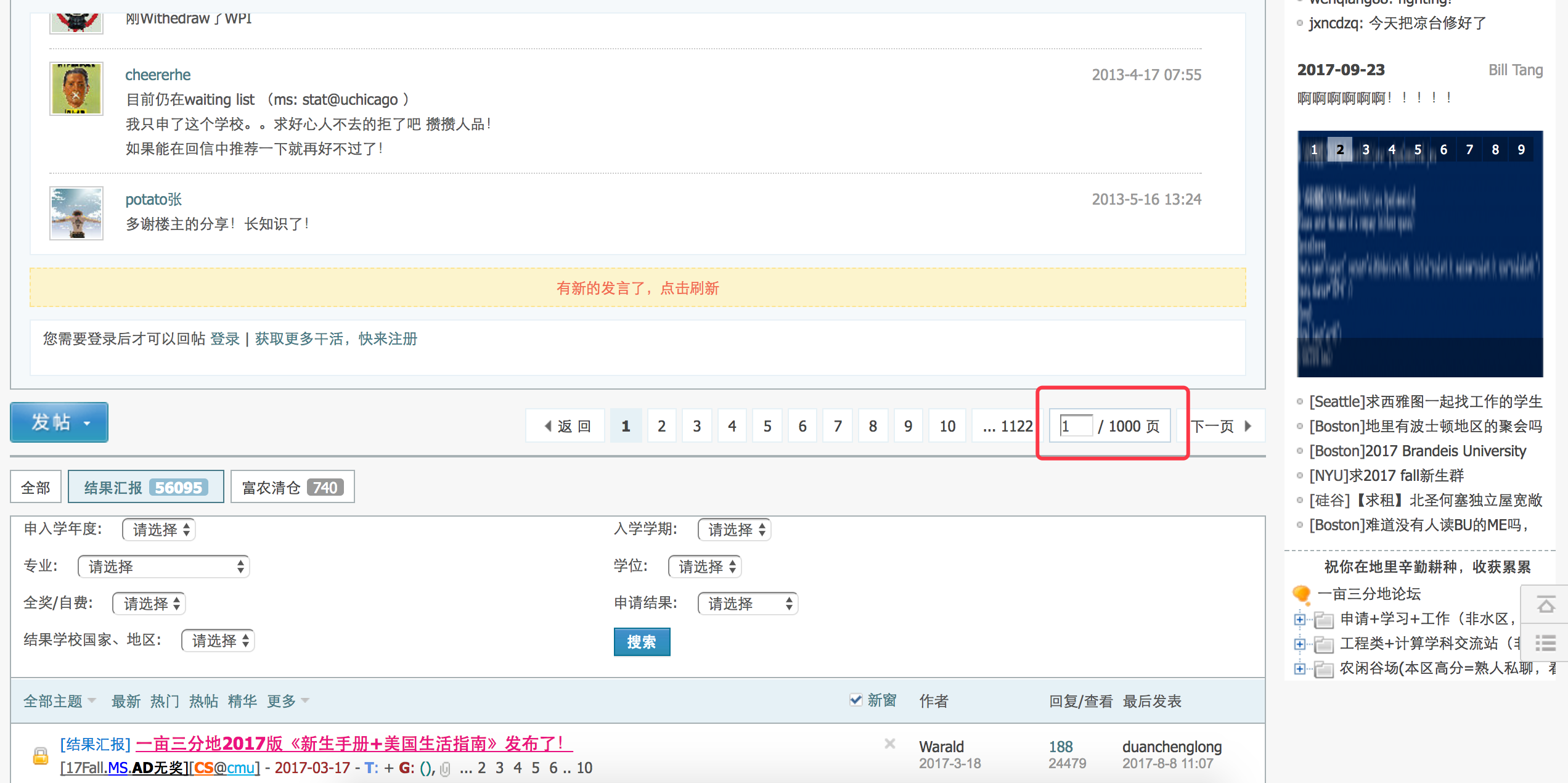
首先我们确定一下有多少录取汇报帖子。
查看网页源码定位到下面这段html代码。1
<a class="bm_h" href="javascript:;" rel="forum.php?mod=forumdisplay&fid=82&sortid=164&%1=&sortid=164&page=2" curpage="1" id="autopbn" totalpage="1000" picstyle="0" forumdefstyle="">下一页 »</a>
下面这行代码获取帖子数。
1
num = int(doc('#autopbn').attr('totalpage'))# 获取页数
观察帖子的URL可以看到不用的帖子的区别在于后面的数据不同,而且这个数子的范围就在上面获取的帖子数内,所以我们就很容易可以构造出我们的真正要爬的网页的URL。
1
page_url = 'http://www.1point3acres.com/bbs/forum-82-%s.html' % index
设置多线程
根据系统的核数设置线程的数目。开启多线程可以加快我们的爬取速度。1
pool = Pool(8)
爬取网页
上面已经拿到了所有的URL。根据这个URL用urllib2去获取网页内容就可以了。1
2page = urllib2.urlopen(url)
content = page.read()解析网页
其实上面已经用到了解析的方法,就是采用pyquery去定位到我们感兴趣的内容。保存数据
解析到网页后可以设计好一定的格式去保存数据。建议采用CSV格式,即以逗号分隔。这个格式Excel也可以很方面的打开处理。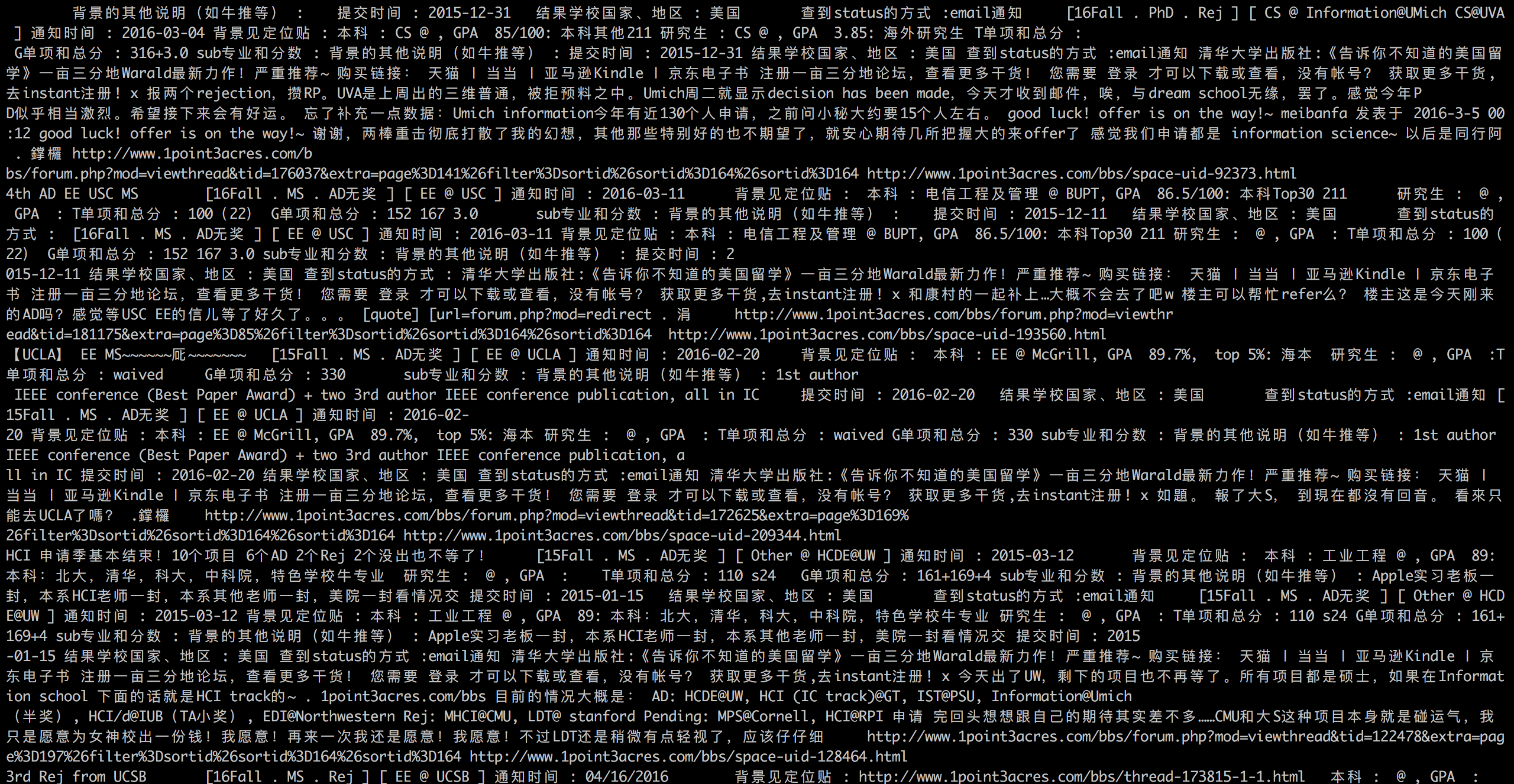
数据清理及分析
爬下来的数据可能包含一些脏数据,可以用正则表达式来做数据清洗。(下次有时间我会写一篇关于正则表达式方面的经验。)
完整源码
1 | #!/usr/bin/python |
这篇文章是针对非计算机专业的同学写的,如果有不清楚的地方欢迎在下面留言。我会不断完善这篇文章,希望能帮到大家。